MSSQL.import_data¶
- MSSQL.import_data(data, table_name, schema_name=None, if_exists='fail', force_replace=False, chunk_size=None, dtype=None, method='multi', index=False, geom_column_name=None, srid=None, confirmation_required=True, verbose=False, **kwargs)[source]¶
Import tabular data into the database.
See also [DBMS-MS-ID-1].
- Parameters:
data (pandas.DataFrame | pandas.io.parsers.TextFileReader | list | tuple) – Tabular data to be imported into the database. It can be a dataframe, a
TextFileReaderor a list/tuple of tuples.table_name (str) – Name of the table where the data will be imported.
schema_name (str | None) – Name of the schema where the table is located; defaults to
DEFAULT_SCHEMA(i.e.'master') ifschema_name=None.if_exists (str) –
Action to take if the table already exists:
'replace': Drop the table before inserting new data.'append': Insert new data to the existing table.'fail': Raise a ValueError if the table already exists (default).
force_replace (bool) – Whether to force replace the existing table; defaults to
False.chunk_size (int | None) – Number of rows to insert at a time; defaults to
None(all at once).dtype (dict | None) – Dictionary specifying column data types; defaults to
None.method (str | None | Callable) –
Method for SQL insertion clause:
None: Uses standard SQLINSERTclause (one per row).'multi': Passes multiple values in a singleINSERTclause (default).
index (bool) – Whether to include the DataFrame index as a column in the database table.
geom_column_name (str | None) – Name of the geometry column if importing spatial data; defaults to
None.srid (int | None) – Spatial Reference Identifier (SRID) associated with the coordinate system, tolerance and resolution; defaults to
None.confirmation_required (bool) – Whether to prompt a confirmation message before proceeding; defaults to
True.verbose (bool | int) – Whether to print detailed information during the import process; defaults to
False.kwargs – [Optional] Additional parameters for the method pandas.DataFrame.to_sql().
Examples:
>>> from pyhelpers.dbms import MSSQL >>> from pyhelpers._cache import example_dataframe >>> testdb = MSSQL(database_name='testdb', verbose=True) Creating a database: [testdb] ... Done. Connecting <server_name>@localhost:1433/testdb ... Successfully. >>> example_df = example_dataframe() >>> example_df Longitude Latitude City London -0.127647 51.507322 Birmingham -1.902691 52.479699 Manchester -2.245115 53.479489 Leeds -1.543794 53.797418 >>> test_table_name = 'example_df' >>> testdb.import_data(example_df, test_table_name, index=True, verbose=2) To import data into [dbo].[example_df] at <server_name>@localhost:1433/testdb ? [No]|Yes: yes Importing the data into the table [dbo].[example_df] ... Done.
The imported example data can also be viewed using Microsoft SQL Server Management Studio (as illustrated in Figure 20 below):
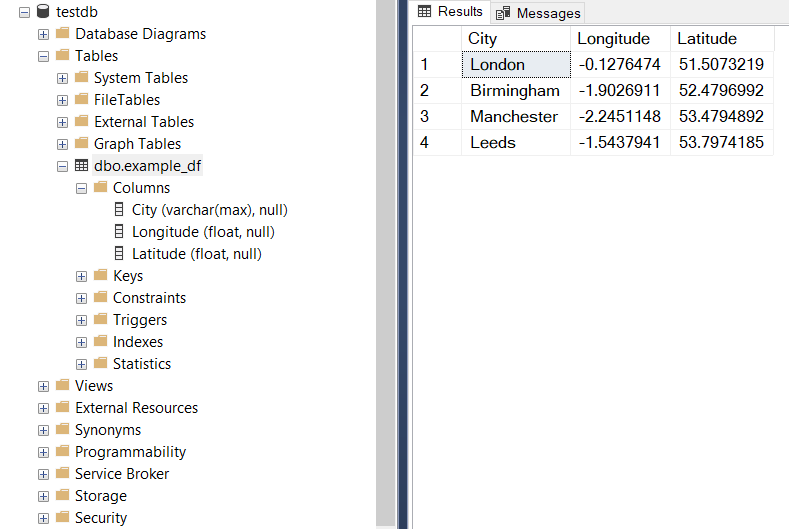
Figure 20 The table [dbo].[example_df] in the database [testdb].¶
>>> # Drop/delete the table [dbo].[example_df] >>> testdb.drop_table(table_name=test_table_name, verbose=True) To drop the table [dbo].[example_df] from <server_name>@localhost:1433/testdb ? [No]|Yes: yes Dropping [dbo].[example_df] ... Done. >>> # Drop/delete the database [testdb] >>> testdb.drop_database(verbose=True) To drop the database [testdb] from <server_name>@localhost:1433 ? [No]|Yes: yes Dropping [testdb] ... Done.
See also
Examples for the method
read_table().