Quick Start¶
This quick-start tutorial provides some simple examples for each of the Subpackages. These examples demonstrate the capabilities of pyhelpers in assisting with data manipulation tasks.
Preparation - Create a data set¶
Let’s start by creating an example data set using NumPy and Pandas, both of which are installed automatically with pyhelpers, as they are dependencies.
To demonstrate, we will use the numpy.random.rand() function to generate a 8×8 NumPy array of random samples drawn from a standard uniform distribution, naming the array random_array:
>>> import numpy as np # Import NumPy and abbreviate it to 'np'
>>> np.random.seed(0) # Ensure that the generated array data is reproducible
>>> random_array = np.random.rand(8, 8)
>>> random_array
array([[0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ,
0.64589411, 0.43758721, 0.891773 ],
[0.96366276, 0.38344152, 0.79172504, 0.52889492, 0.56804456,
0.92559664, 0.07103606, 0.0871293 ],
[0.0202184 , 0.83261985, 0.77815675, 0.87001215, 0.97861834,
0.79915856, 0.46147936, 0.78052918],
[0.11827443, 0.63992102, 0.14335329, 0.94466892, 0.52184832,
0.41466194, 0.26455561, 0.77423369],
[0.45615033, 0.56843395, 0.0187898 , 0.6176355 , 0.61209572,
0.616934 , 0.94374808, 0.6818203 ],
[0.3595079 , 0.43703195, 0.6976312 , 0.06022547, 0.66676672,
0.67063787, 0.21038256, 0.1289263 ],
[0.31542835, 0.36371077, 0.57019677, 0.43860151, 0.98837384,
0.10204481, 0.20887676, 0.16130952],
[0.65310833, 0.2532916 , 0.46631077, 0.24442559, 0.15896958,
0.11037514, 0.65632959, 0.13818295]])
>>> random_array.shape # Check the shape of the array
(8, 8)
Next, we will use pandas.DataFrame() to transform random_array into a Pandas DataFrame, naming it data_frame:
>>> import pandas as pd # Import Pandas and abbreviate it to 'pd'
>>> data_frame = pd.DataFrame(random_array, columns=['col_' + str(x) for x in range(8)])
>>> data_frame
col_0 col_1 col_2 ... col_5 col_6 col_7
0 0.548814 0.715189 0.602763 ... 0.645894 0.437587 0.891773
1 0.963663 0.383442 0.791725 ... 0.925597 0.071036 0.087129
2 0.020218 0.832620 0.778157 ... 0.799159 0.461479 0.780529
3 0.118274 0.639921 0.143353 ... 0.414662 0.264556 0.774234
4 0.456150 0.568434 0.018790 ... 0.616934 0.943748 0.681820
5 0.359508 0.437032 0.697631 ... 0.670638 0.210383 0.128926
6 0.315428 0.363711 0.570197 ... 0.102045 0.208877 0.161310
7 0.653108 0.253292 0.466311 ... 0.110375 0.656330 0.138183
[8 rows x 8 columns]
See also
The example of saving data as a Pickle file.
Altering display settings¶
< Previous | Back to Top | Next >
The pyhelpers.settings module can be used to alter frequently-used parameters (of GDAL, Matplotlib, NumPy and Pandas) to customise the working environment.
For example, we can apply the np_preferences() function with its default parameters to get a neater view of random_array:
>>> from pyhelpers.settings import np_preferences
>>> # To round the numbers to four decimal places
>>> np_preferences() # By default, reset=False and precision=4
>>> random_array
array([[0.5488, 0.7152, 0.6028, 0.5449, 0.4237, 0.6459, 0.4376, 0.8918],
[0.9637, 0.3834, 0.7917, 0.5289, 0.5680, 0.9256, 0.0710, 0.0871],
[0.0202, 0.8326, 0.7782, 0.8700, 0.9786, 0.7992, 0.4615, 0.7805],
[0.1183, 0.6399, 0.1434, 0.9447, 0.5218, 0.4147, 0.2646, 0.7742],
[0.4562, 0.5684, 0.0188, 0.6176, 0.6121, 0.6169, 0.9437, 0.6818],
[0.3595, 0.4370, 0.6976, 0.0602, 0.6668, 0.6706, 0.2104, 0.1289],
[0.3154, 0.3637, 0.5702, 0.4386, 0.9884, 0.1020, 0.2089, 0.1613],
[0.6531, 0.2533, 0.4663, 0.2444, 0.1590, 0.1104, 0.6563, 0.1382]])
To reset the display settings, set reset=True to revert to default values:
>>> np_preferences(reset=True)
>>> random_array
array([[0.54881350, 0.71518937, 0.60276338, 0.54488318, 0.42365480,
0.64589411, 0.43758721, 0.89177300],
[0.96366276, 0.38344152, 0.79172504, 0.52889492, 0.56804456,
0.92559664, 0.07103606, 0.08712930],
[0.02021840, 0.83261985, 0.77815675, 0.87001215, 0.97861834,
0.79915856, 0.46147936, 0.78052918],
[0.11827443, 0.63992102, 0.14335329, 0.94466892, 0.52184832,
0.41466194, 0.26455561, 0.77423369],
[0.45615033, 0.56843395, 0.01878980, 0.61763550, 0.61209572,
0.61693400, 0.94374808, 0.68182030],
[0.35950790, 0.43703195, 0.69763120, 0.06022547, 0.66676672,
0.67063787, 0.21038256, 0.12892630],
[0.31542835, 0.36371077, 0.57019677, 0.43860151, 0.98837384,
0.10204481, 0.20887676, 0.16130952],
[0.65310833, 0.25329160, 0.46631077, 0.24442559, 0.15896958,
0.11037514, 0.65632959, 0.13818295]])
Note
The
np_preferences()function inherits the functionality of numpy.set_printoptions(), with some modifications.
Similarly, the pd_preferences() function alters a few Pandas options and settings, such as display representation and maximum number of columns when displaying a DataFrame. Applying the function with default parameters allows us to view all eight columns with precision set to four decimal places.
>>> from pyhelpers.settings import pd_preferences
>>> pd_preferences() # By default, reset=False and precision=4
>>> data_frame
col_0 col_1 col_2 col_3 col_4 col_5 col_6 col_7
0 0.5488 0.7152 0.6028 0.5449 0.4237 0.6459 0.4376 0.8918
1 0.9637 0.3834 0.7917 0.5289 0.5680 0.9256 0.0710 0.0871
2 0.0202 0.8326 0.7782 0.8700 0.9786 0.7992 0.4615 0.7805
3 0.1183 0.6399 0.1434 0.9447 0.5218 0.4147 0.2646 0.7742
4 0.4562 0.5684 0.0188 0.6176 0.6121 0.6169 0.9437 0.6818
5 0.3595 0.4370 0.6976 0.0602 0.6668 0.6706 0.2104 0.1289
6 0.3154 0.3637 0.5702 0.4386 0.9884 0.1020 0.2089 0.1613
7 0.6531 0.2533 0.4663 0.2444 0.1590 0.1104 0.6563 0.1382
To reset the settings, use the parameter reset; setting it to True reverts to default values, and setting it to 'all' resets all Pandas options:
>>> pd_preferences(reset=True)
>>> data_frame
col_0 col_1 col_2 ... col_5 col_6 col_7
0 0.548814 0.715189 0.602763 ... 0.645894 0.437587 0.891773
1 0.963663 0.383442 0.791725 ... 0.925597 0.071036 0.087129
2 0.020218 0.832620 0.778157 ... 0.799159 0.461479 0.780529
3 0.118274 0.639921 0.143353 ... 0.414662 0.264556 0.774234
4 0.456150 0.568434 0.018790 ... 0.616934 0.943748 0.681820
5 0.359508 0.437032 0.697631 ... 0.670638 0.210383 0.128926
6 0.315428 0.363711 0.570197 ... 0.102045 0.208877 0.161310
7 0.653108 0.253292 0.466311 ... 0.110375 0.656330 0.138183
[8 rows x 8 columns]
Note
The functions in
pyhelpers.settingshandle only a few selected parameters based on the author’s preferences. Feel free to modify the source code to suit your needs.
Specify a directory or file path¶
< Previous | Back to Top | Next >
The pyhelpers.dirs module aids in manipulating directories. For instance, the cd() function returns the absolute path to the current working directory, or to a specified subdirectory or file within it:
>>> from pyhelpers.dirs import cd
>>> from pyhelpers.dirs import normalize_pathname # Optional, for printing uniform pathnames
>>> import os
>>> cwd = cd() # The current working directory
>>> # Relative path of `cwd` to the current working directory
>>> rel_path_cwd = os.path.relpath(cwd)
>>> print(rel_path_cwd)
.
To specify a path to a temporary folder named "pyhelpers_tutorial":
>>> # Name of a temporary folder for this tutorial
>>> dir_name = "pyhelpers_tutorial"
>>> # Path to the folder "pyhelpers_tutorial"
>>> path_to_dir = cd(dir_name)
>>> # Relative path of the directory
>>> rel_dir_path = os.path.relpath(path_to_dir)
>>> print(rel_dir_path)
pyhelpers_tutorial
Check whether the directory "pyhelpers_tutorial" exists:
>>> print(f'Does the directory "{rel_dir_path}" exist? {os.path.isdir(path_to_dir)}')
Does the directory "pyhelpers_tutorial" exist? False
If the directory "pyhelpers_tutorial" does not exist, set the parameter mkdir=True to create it:
>>> # Set `mkdir` to `True` to create the "pyhelpers_tutorial" folder
>>> path_to_dir = cd(dir_name, mkdir=True)
>>> # Check again whether the directory "pyhelpers_tutorial" exists
>>> print(f'Does the directory "{rel_dir_path}" exist? {os.path.isdir(path_to_dir)}')
Does the directory "pyhelpers_tutorial" exist? True
When we specify a sequence of names (in order with a filename being the last), the cd() function would assume that all the names prior to the filename are folder names, which specify a path to the file. For example, to specify a path to a file named "quick_start.dat" within the "pyhelpers_tutorial" folder:
>>> # Name of the file
>>> filename = "quick_start.dat"
>>> # Path to the file named "quick_start.dat"
>>> path_to_file = cd(dir_name, filename) # path_to_file = cd(path_to_dir, filename)
>>> # Relative path of the file "quick_start.dat"
>>> rel_file_path = os.path.relpath(path_to_file)
>>> # [Optional]
>>> rel_file_path = normalize_pathname(os.path.relpath(path_to_file))
>>> print(rel_file_path)
pyhelpers_tutorial/quick_start.dat
If any directories in the specified path do not exist, setting mkdir=True will create them. For example, to specify a data directory named "data" within the "pyhelpers_tutorial" folder:
>>> # Path to the data directory
>>> data_dir = cd(dir_name, "data") # equivalent to `cd(path_to_dir, "data")`
>>> # Relative path of the data directory
>>> rel_data_dir = os.path.relpath(data_dir)
>>> # [Optional]
>>> rel_data_dir = normalize_pathname(os.path.relpath(data_dir))
>>> print(rel_data_dir)
pyhelpers_tutorial/data
We can then use the is_dir() function to check if data_dir (or rel_data_dir) is a directory:
>>> from pyhelpers.dirs import is_dir
>>> # Check if `rel_data_dir` is a directory
>>> print(f'Does `rel_data_dir` specify a directory path? {is_dir(rel_data_dir)}')
Does `rel_data_dir` specify a directory path? True
>>> # Check if the data directory exists
>>> print(f'Does the directory "{rel_data_dir}" exist? {os.path.isdir(rel_data_dir)}')
Does the directory "pyhelpers_tutorial/data" exist? False
For another example, to specify a path to a Pickle file, named "dat.pkl", in the directory "pyhelpers_tutorial/data":
>>> # Name of the Pickle file
>>> pickle_filename = "dat.pkl"
>>> # Path to the Pickle file
>>> path_to_pickle = cd(data_dir, pickle_filename)
>>> # Relative path of the Pickle file
>>> rel_pickle_path = os.path.relpath(path_to_pickle)
>>> # [Optional]
>>> rel_pickle_path = normalize_pathname(os.path.relpath(path_to_pickle))
>>> print(rel_pickle_path)
pyhelpers_tutorial/data/dat.pkl
Check rel_pickle_path (or path_to_pickle):
>>> # Check if `rel_pickle_path` is a directory
>>> print(f'Is `rel_pickle_path` a directory? {os.path.isdir(rel_pickle_path)}')
Is `rel_pickle_path` a directory? False
>>> # Check if the file "dat.pkl" exists
>>> print(f'Does the file "{rel_pickle_path}" exist? {os.path.isfile(rel_pickle_path)}')
Does the file "pyhelpers_tutorial/data/dat.pkl" exist? False
Let’s now set mkdir=True to create any missing directories:
>>> path_to_pickle = cd(data_dir, pickle_filename, mkdir=True)
>>> rel_data_dir = os.path.relpath(data_dir)
>>> # [Optional]
>>> rel_data_dir = normalize_pathname(os.path.relpath(data_dir))
>>> # Check again if the data directory exists
>>> print(f'Does the directory "{rel_data_dir}" exist? {os.path.isdir(rel_data_dir)}')
Does the directory "pyhelpers_tutorial/data" exist? True
>>> # Check again if the file "dat.pkl" exists
>>> print(f'Does the file "{rel_pickle_path}" exist? {os.path.isfile(rel_pickle_path)}')
Does the file "pyhelpers_tutorial/data/dat.pkl" exist? False
[See also the example of saving data as a Pickle file.]
To delete the directory "pyhelpers_tutorial" (including all its contents), we can use the delete_dir() function:
>>> from pyhelpers.dirs import delete_dir
>>> # Delete the "pyhelpers_tutorial" directory
>>> delete_dir(path_to_dir, verbose=True)
To delete the directory "./pyhelpers_tutorial/" (Not empty)
? [No]|Yes: yes
Deleting "./pyhelpers_tutorial/" ... Done.
Save and load data with Pickle files¶
< Previous | Back to Top | Next >
The pyhelpers.store module can facilitate tasks such as saving and loading data using file-like objects in common formats such as CSV, JSON, and Pickle.
To demonstrate, let’s save the data_frame created earlier (see Preparation) as a Pickle file using save_pickle(), and later retrieve it using load_pickle(). We’ll use path_to_pickle from the directory specified in the Specify a directory or a file path section:
>>> from pyhelpers.store import save_pickle, load_pickle
>>> # Save `data_frame` to "dat.pkl"
>>> save_pickle(data_frame, path_to_pickle, verbose=True)
Saving "dat.pkl" to "./pyhelpers_tutorial/data/" ... Done.
We can now retrieve/load the data from path_to_pickle and store it as df_retrieved:
>>> df_retrieved = load_pickle(path_to_pickle, verbose=True)
Loading "./pyhelpers_tutorial/data/dat.pkl" ... Done.
To verify if df_retrieved matches data_frame:
>>> print(f'`df_retrieved` matches `data_frame`? {df_retrieved.equals(data_frame)}')
`df_retrieved` matches `data_frame`? True
Before proceeding, let’s delete the Pickle file (i.e. path_to_pickle) and the associated directory that’s been created:
>>> delete_dir(path_to_dir, verbose=True)
To delete the directory "./pyhelpers_tutorial/" (Not empty)
? [No]|Yes: yes
Deleting "./pyhelpers_tutorial/" ... Done.
Note
In the
pyhelpers.storemodule, some functions such assave_spreadsheet()andsave_spreadsheets()may require openpyxl, XlsxWriter or xlrd, which are not essential dependencies for the base installation of pyhelpers. We could install them when needed via an appropriate method such aspip install.
Convert coordinates between OSGB36 and WGS84¶
< Previous | Back to Top | Next >
The pyhelpers.geom module can assist us in manipulating geometric and geographical data. For example, we can use the osgb36_to_wgs84() function to convert geographical coordinates from OSGB36 (British national grid) eastings and northings to WGS84 longitudes and latitudes:
>>> from pyhelpers.geom import osgb36_to_wgs84
>>> # Convert coordinates (easting, northing) to (longitude, latitude)
>>> easting, northing = 530039.558844, 180371.680166 # London
>>> longitude, latitude = osgb36_to_wgs84(easting, northing)
>>> (longitude, latitude)
(-0.12764738750268856, 51.507321895400686)
We can also use the function for bulk conversion of an array of OSGB36 coordinates:
>>> from pyhelpers._cache import example_dataframe
>>> example_df = example_dataframe(osgb36=True)
>>> example_df
Easting Northing
City
London 530039.558844 180371.680166
Birmingham 406705.887014 286868.166642
Manchester 383830.039036 398113.055831
Leeds 430147.447354 433553.327117
>>> xy_array = example_df.to_numpy()
>>> eastings, northings = xy_array.T
>>> lonlat_array = osgb36_to_wgs84(eastings, northings, as_array=True)
>>> lonlat_array
array([[-0.12764739, 51.50732190],
[-1.90269109, 52.47969920],
[-2.24511479, 53.47948920],
[-1.54379409, 53.79741850]])
Similarly, conversion from (longitude, latitude) back to (easting, northing) can be implemented using the function wgs84_to_osgb36():
>>> from pyhelpers.geom import wgs84_to_osgb36
>>> longitudes, latitudes = lonlat_array.T
>>> xy_array_ = wgs84_to_osgb36(longitudes, latitudes, as_array=True)
>>> xy_array_
array([[530039.55972534, 180371.67967567],
[406705.88783629, 286868.16621896],
[383830.03985454, 398113.05550332],
[430147.44820845, 433553.32682598]])
Note
Conversion of coordinates between different systems may inevitably introduce minor errors, which are typically negligible.
Check if xy_array_ is almost equal to xy_array:
>>> eq_res = np.array_equal(np.round(xy_array, 2), np.round(xy_array_, 2))
>>> print(f'Is `xy_array_` almost equal to `xy_array`? {eq_res}')
Is `xy_array_` almost equal to `xy_array`? True
Find similar texts¶
< Previous | Back to Top | Next >
The pyhelpers.text module can assist us in manipulating textual data. For example, suppose we have a word 'angle', which is stored in a str-type variable named word, and a list of words, which is stored in a list-type variable named lookup_list; if we’d like to find from the list a one that is most similar to 'angle', we can use the function find_similar_str():
>>> from pyhelpers.text import find_similar_str
>>> word = 'angle'
>>> lookup_list = [
... 'Anglia',
... 'East Coast',
... 'East Midlands',
... 'North and East',
... 'London North Western',
... 'Scotland',
... 'South East',
... 'Wales',
... 'Wessex',
... 'Western']
>>> # Find the most similar word to 'angle'
>>> result_1 = find_similar_str(word, lookup_list)
>>> result_1
'Anglia'
By default, the function relies on difflib - a built-in Python module. Alternatively, we can make use of an open-source package, RapidFuzz, via setting the parameter engine='rapidfuzz' (or simply engine='fuzz'):
>>> # Find the most similar word to 'angle' by using RapidFuzz
>>> result_2 = find_similar_str(word, lookup_list, engine='fuzz')
>>> result_2
'Anglia'
Download an image file¶
< Previous | Back to Top | Next >
The pyhelpers.ops module provides various helper functions for operations. For example, we can use download_file_from_url() to download files from URLs.
Let’s now try to download the Python logo image from its official page. Firstly, we need to specify the URL of the image file:
>>> from pyhelpers.ops import download_file_from_url
>>> # URL of a .png file of the Python logo
>>> url = 'https://www.python.org/static/community_logos/python-logo-master-v3-TM.png'
Then, we need to specify a directory where we’d like to save the image file, and a filename for it; let’s say we want to name the file "python-logo.png" and save it to the directory "pyhelpers_tutorial/images":
>>> python_logo_filename = "python-logo.png"
>>> # python_logo_file_path = cd(dir_name, "images", python_logo_filename)
>>> python_logo_file_path = cd(path_to_dir, "images", python_logo_filename)
>>> # Download the .png file of the Python logo
>>> download_file_from_url(url, python_logo_file_path, verbose=False)
Note
By default,
verbose=Falseprevents output during download.Setting
verbose=True(orverbose=1) requires an the package tqdm, which is not essential for installing pyhelpers. We can install it viapip install tqdmif necessary.
If we set verbose=True (given that tqdm is available in our working environment), the function will print out relevant information about the download progress as the file is being downloaded:
>>> download_file_from_url(url, python_logo_file_path, if_exists='replace', verbose=True)
Downloading "python-logo.png" 100%|██████████| 83.6k/83.6k | 403kB/s | ETA: 00:00
Updating "python-logo.png" in "./pyhelpers_tutorial/images/" ... Done.
>>> # Use a different progress bar color
>>> download_file_from_url(
... url, python_logo_file_path, if_exists='replace', pbar_color='green', verbose=True)
Downloading "python-logo.png" 100%|██████████| 83.6k/83.6k | 760kB/s | ETA: 00:00
Updating "python-logo.png" in "./pyhelpers_tutorial/images/" ... Done.
Note
‘403kB/s’ shown at the end of the output is an estimated speed of downloading the file, which varies depending on network conditions at the time of running the function.
Setting
if_exists='replace'(default) allows us to replace the image file that already exists at the specified destination.
Now let’s have a look at the downloaded image file using Pillow:
>>> from PIL import Image
>>> python_logo = Image.open(python_logo_file_path)
>>> python_logo.show()

Figure 1 Python Logo (for illustrative purposes in this tutorial).¶
Note
In Jupyter Notebook, we can use IPython.display.Image to display the image in the notebook by running
IPython.display.Image(python_logo_file_path).
To delete "pyhelpers_tutorial" and its subdirectories (including "pyhelpers_tutorial/images"), we can use the delete_dir() function again:
>>> delete_dir(path_to_dir, confirmation_required=False, verbose=True)
Deleting "./pyhelpers_tutorial/" ... Done.
Setting the parameter confirmation_required=False can allow us to delete the directory straightaway without typing a yes to confirm the action. The confirmation prompt is actually implemented through the confirmed() function, which is also from the pyhelpers.ops module and can be helpful especially when we’d like to impose a manual confirmation before proceeding with certain actions. For example:
>>> from pyhelpers.ops import confirmed
>>> # We can specify any prompting message as to what needs to be confirmed.
>>> if confirmed(prompt="Continue? ..."):
... print("OK! Go ahead.")
Continue? ... [No]|Yes: yes
OK! Go ahead.
Note
The response to the
confirmed()prompt is case-insensitive. It does not have to be exactlyYesfor the function to returnTrue; responses such asyes,Yoryewill also work. Conversely, responses such asnoornwill returnFalse.The
confirmed()function also includes a parameterconfirmation_required, which defaults toTrue. If we setconfirmation_required=False, no confirmation is required, and the function will become ineffective and returnTrue.
Work with a PostgreSQL server¶
< Previous | Back to Top | Next >
The pyhelpers.dbms module provides a convenient way of communicating with databases, such as PostgreSQL and Microsoft SQL Server.
For example, the PostgreSQL class can assist us in executing basic SQL statements on a PostgreSQL database server. To demonstrate its functionality, let’s start by importing the class:
>>> from pyhelpers.dbms import PostgreSQL
Connect to a database¶
Now, we can create an instance of the class PostgreSQL to connect to a PostgreSQL server by specifying key parameters, including host, port, username, database_name and password.
Note
If
host,port,usernameanddatabase_nameare unspecified, their associated default attributes (namely,DEFAULT_HOST,DEFAULT_PORT,DEFAULT_USERNAMEandDEFAULT_DATABASE) are used to instantiate the class, in which case we will connect to the default PostgreSQL server (as is installed on a PC).If the specified
database_namedoes not exist, it will be automatically created during the class instantiation.Usually, we do not specify the parameter
passwordexplicitly in our code. Leaving it asNoneby default, we will be prompted to type it manually when instantiating the class.
For example, let’s create an instance named postgres and establish a connection with a database named “pyhelpers_tutorial”, hosted on the default PostgreSQL server:
>>> database_name = "pyhelpers_tutorial"
>>> postgres = PostgreSQL(database_name=database_name, verbose=True)
Password (postgres@localhost:5432): ***
Creating a database: "pyhelpers_tutorial" ... Done.
Connecting postgres:***@localhost:5432/pyhelpers_tutorial ... Successfully.
We can use pgAdmin, the most popular graphical management tool for PostgreSQL, to check whether the database “pyhelpers_tutorial” exists in the Databases tree of the default server, as illustrated in Figure 2:
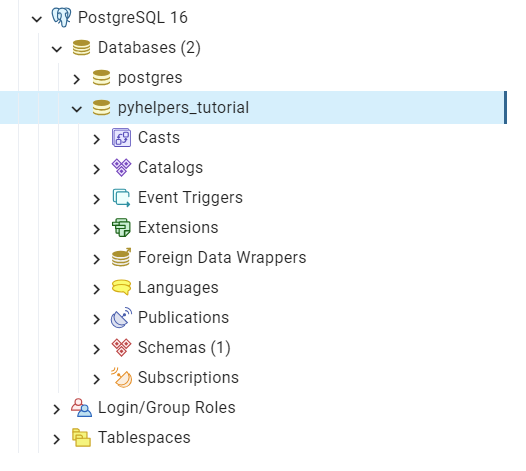
Figure 2 The database “pyhelpers_tutorial”.¶
Alternatively, we can use the database_exists() method:
>>> res = postgres.database_exists(database_name)
>>> print(f'Does the database "{database_name}" exist? {res}')
Does the database "pyhelpers_tutorial" exist? True
>>> print(f'We are currently connected to the database "{postgres.database_name}".')
We are currently connected to the database "pyhelpers_tutorial".
On the same server, we can create multiple databases. For example, let’s create another database named “pyhelpers_tutorial_alt” using the create_database() method:
>>> database_name_ = "pyhelpers_tutorial_alt"
>>> postgres.create_database(database_name_, verbose=True)
Creating a database: "pyhelpers_tutorial_alt" ... Done.
As we can see in Figure 3, the database “pyhelpers_tutorial_alt” has now been added to the default Databases tree:
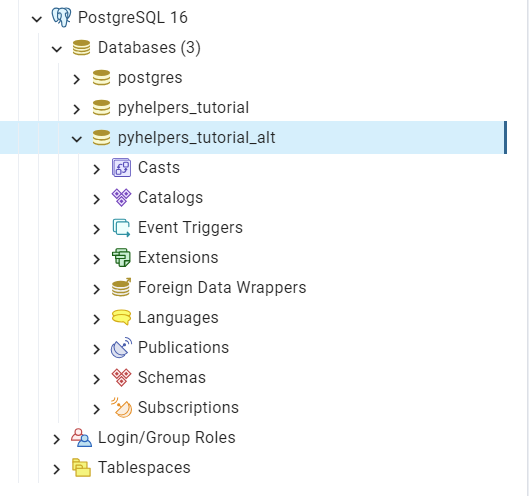
Figure 3 The database “pyhelpers_tutorial_alt”.¶
Note
When a new database is created, the instance
postgresdisconnects from the current database and connects to the new one.
Check whether “pyhelpers_tutorial_alt” is the currently connected database:
>>> res = postgres.database_exists("pyhelpers_tutorial_alt")
>>> print(f'Does the database "{database_name_}" exist? {res}')
Does the database "pyhelpers_tutorial_alt" exist? True
>>> print(f'We are currently connected to the database "{postgres.database_name}".')
We are currently connected to the database "pyhelpers_tutorial_alt".
To reconnect to “pyhelpers_tutorial” (database_name), we can use the connect_database() method:
>>> postgres.connect_database(database_name, verbose=True)
Connecting postgres:***@localhost:5432/pyhelpers_tutorial ... Successfully.
>>> print(f'We are currently connected to the database "{postgres.database_name}".')
We are now connected with the database "pyhelpers_tutorial".
Import data into a database¶
With the established connection to the database, we can use the import_data() method to import the data_frame (created in the Preparation section) into a table named “df_table” under the default schema “public”:
>>> table_name = "df_table"
>>> postgres.import_data(data=data_frame, table_name=table_name, verbose=True)
To import data into the table "public"."df_table" at postgres:***@localhost:5432/...
? [No]|Yes: yes
Importing the data into "public"."df_table" ... Done.
We should now see the table in pgAdmin, as shown in Figure 4:
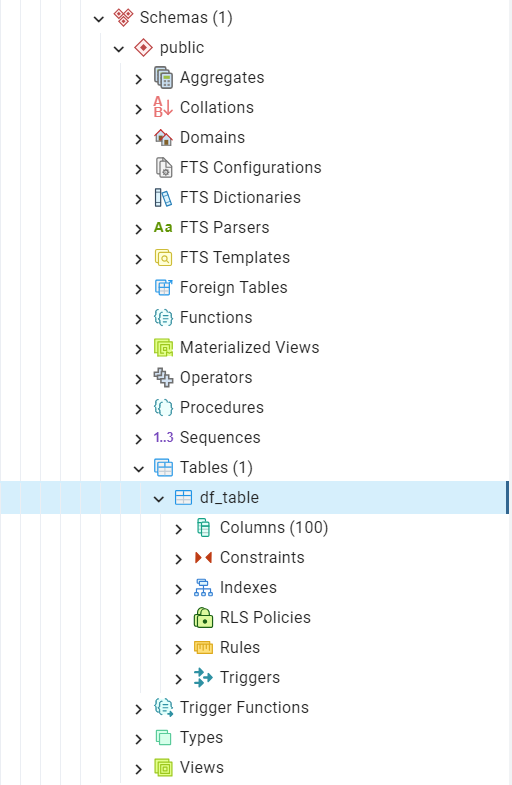
Figure 4 The table “public”.”df_table”.¶
The method import_data() relies on the method pandas.DataFrame.to_sql(), with the method parameter set to 'multi' by default. Optionally, we can also use the method psql_insert_copy() to significantly speed up data import, especially for large data sets.
Let’s now try to import the same data into a table named “df_table_alt” by setting method=postgres.psql_insert_copy:
>>> table_name_ = "df_table_alt"
>>> postgres.import_data(
... data=data_frame, table_name=table_name_, method=postgres.psql_insert_copy,
... verbose=True)
To import data into the table "public"."df_table_alt" at postgres:***@localhost:5432/...
? [No]|Yes: yes
Importing the data into "public"."df_table_alt" ... Done.
In pgAdmin, we can see the table has been added to the Tables list, as shown in Figure 5:
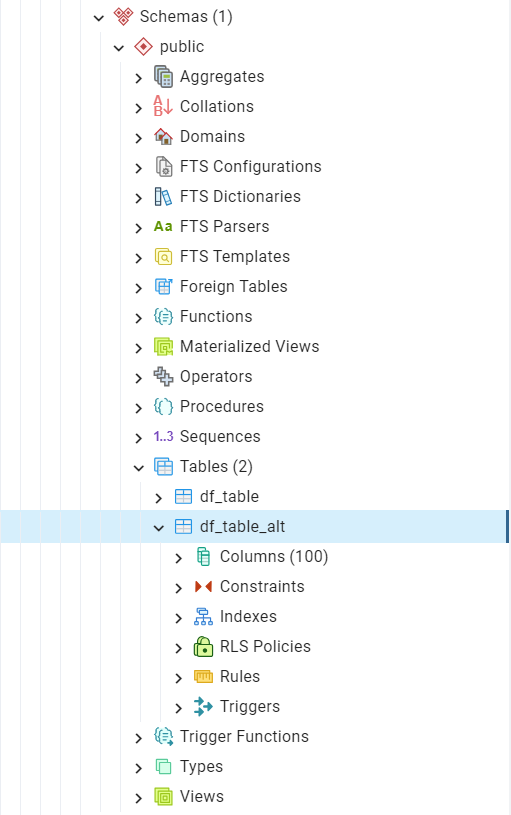
Figure 5 The table “public”.”df_table_alt”.¶
Fetch data from a database¶
To retrieve the imported data, we can use the read_table() method:
>>> df_retrieval_1 = postgres.read_table(table_name)
>>> res = df_retrieval_1.equals(data_frame)
>>> print(f"Is `df_retrieval_1` equal to `data_frame`? {res}")
Is `df_retrieval_1` equal to `data_frame`? True
Alternatively, we can use the read_sql_query() method, which serves as a more flexible way of reading/querying data. It takes PostgreSQL query statements and can be much faster for large tables.
Let’s try this method to fetch the same data from the table “df_table_alt”:
>>> df_retrieval_2 = postgres.read_sql_query('SELECT * FROM "public"."df_table_alt"')
>>> res = df_retrieval_2.round(8).equals(df_retrieval_1.round(8))
>>> print(f"Is `df_retrieval_2` equal to `df_retrieval_1`? {res}")
Is `df_retrieval_2` equal to `df_retrieval_1`? True
Note
For the
read_sql_query()method, any PostgreSQL query statement that is passed tosql_queryshould NOT end with';'.
Delete data¶
Before we leave this notebook, let’s clear up the databases and tables we’ve created.
We can delete/drop a table (e.g. “df_table”) using the drop_table() method:
>>> postgres.drop_table(table_name=table_name, verbose=True)
To drop the table "public"."df_table" from postgres:***@localhost:5432/pyhelpers_tutorial
? [No]|Yes: yes
Dropping "public"."df_table" ... Done.
To delete/drop a database, we can use the drop_database() method:
>>> # Drop "pyhelpers_tutorial" (i.e. the currently connected database)
>>> postgres.drop_database(verbose=True)
To drop the database "pyhelpers_tutorial" from postgres:***@localhost:5432
? [No]|Yes: yes
Dropping "pyhelpers_tutorial" ... Done.
>>> # Drop "pyhelpers_tutorial_alt"
>>> postgres.drop_database(database_name=database_name_, verbose=True)
To drop the database "pyhelpers_tutorial_alt" from postgres:***@localhost:5432
? [No]|Yes: yes
Dropping "pyhelpers_tutorial_alt" ... Done.
Check the currently connected database:
>>> print(f"We are currently connected with the database \"{postgres.database_name}\".")
We are currently connected with the database "postgres".
Now we have removed all the databases created in this notebook and restored the PostgreSQL server to its original status.
Any issues regarding the use of pyhelpers are welcome and should be logged/reported onto Issue Tracker.
For more details and examples, check Subpackages.